Collaboration on different document processing platforms
Alan Dix
Research Report - RR9508
at time of publication: hci@hud, The HCI
Research Centre, University of Huddersfield
Research Report - RR9508
at time of publication: hci@hud, The HCI
Research Centre, University of Huddersfield
Coping with different document formats is one of the most difficult technical problems of collaborative writing. Typically people resort to transferring information to one another in plain ASCII, but this means the recipients must constantly add the relevant formatting or mark-up codes for their own word-processor or typesetter. If the same portion of the document is passed back and forth this will mean that the participants will have to add the same formatting several times. Translators between formats can help, but because the formats encode different details, repeated translation will gradually lose information. The alternative, presented in this paper, is to maintain multiple copies in each format and to propagate changes made to one copy to all others. This means that only new text need be marked-up in any format.
Keywords: cooperative work, SGML, platform independence
Much research work and many systems are dedicated to supporting the collaborative writing process - aiding brainstorming, structuring, annotation, sharing drafts etc. (Sharples 1993). However, perhaps the most difficult technical problem is more prosaic - deciding on a common format to exchange data. Each person has their own favourite word-processor or text formatting package. Some would argue that they ought to use an international standard such as SGML or ODA (Schill 1995). However, even if the participants are willing, they may be in different organisations with different corporate standards.
For the examples in this paper, we'll imagine three colleagues Alison, Brian and Clarise. Alison uses LaTeX to produce documents - she works in a computing department with only UNIX workstations and no word-processors! Brian is in a psychology deptartment and uses Word on a Macintosh which produces RTF files. Finally, Clarise works for a European funded project committed to using international standards and so must work in SGML.
Different parts of the document production process may require different formats. For example, an author may prefer to use a word-processor to produce a book as the drafts will be of good quality and suitable to distribute to colleagues for comment. However, the publisher will want to strip most of the word-processor's codes and insert mark-up code for their own typesetter.
Arguably the publishing case is easier than collaborative writing. Only the finished manuscript need be translated from the word-processor to the mark-up system. In collaborative writing the document may change hands and authorship several times during its lifetime. However, even in the case of publishing, the author may make corrections for a reprint, which need to be incorporated into the marked-up version.
Similar problems also arise with other forms of information: databases, spreadsheets, graphics etc. In all these cases one needs a solution which allows diversity of representation but minimises the work of translating back and forth between formats.
Different representations have their own advantages and they typically differ not only in the way they store information, but also in the sort of information they record. Figures 1-5 show this. Figure 1 is a simple memorandum. The RTF for this (with some header information removed) is shown in figure 2. It records primarily presentation information, that some words are bold, centred etc. In a larger document there may be some implicit structural information because of the use of named styles (e.g. 'heading 1') which are also used by the outliner.

In contrast figure 3 shows the SGML version of the document. It only shows the structure, with no presentation details. Note how the 'to' field does not explicitly say that the word 'To:' will be displayed; this is a matter for the recipient's SGML display tools. Similarly there is no explicit indication that the word 'MEMORANDUM' will be displayed or whether it is centred, bold etc. A different SGML display program might format the document as in figure 4.

Finally, figure 5 shows a LaTeX version of the memo. It assumes that a 'memorandum' style file has been designed and that this prints the word 'Memorandum' at the beginning of the document. However, the bold words 'To:', 'From:' etc. are typeset individually. In fact, because TeX is programmable, the memorandum style might also include macros '\To' and '\From' which would print these in bold. So, it combines some of the structure of SGML and some of the presentation of Word, but is not a complete superset of either.

Given the requirement to have the same document in different formats, the most frequent solution is to strip all formatting and send the document between participants in plain ASCII. Any text-processing platform will be able to read and write a document in this format and it can also be sent easily by email [see footnote 1]. In the case of databases and spreadsheets, comma or tab delimited fields fulfil the same purpose.
The recipient may be able to read the imported text as it is, but will have to add formatting information appropriate for their own platform. If the same part of a document is passed back and forth between the same participants, this formatting information will have to be added every time.
One way to reduce this effort is to use automatic translation tools between the formats (figure 6). For example, there are translators which convert an RTF document into LaTeX, and ones which turn both RTF and LaTeX into HTML (the World Wide Web document format which is a particular instance of SGML).
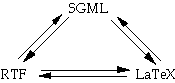
Figure 6 Individual translators
These do not do a perfect job as there are some features which cannot be translated. For example, in LaTeX references to figures can be made using labels whereas in RTF these are absolute numbers. However, it is far better than doing all the work by hand!
In fact, such translators work quite well if all that is required is for one author to see another's work neatly formatted. But it breaks down when the same section is edited by two or more participants in sequence. Each translation loses information and, as the document is translated back and forth, more and more information is lost until all that is left is the common information between the two formats - often little more than ASCII. The situation is exacerbated if the translators come from different vendors, as the different assumptions made may lead to some steady 'drift' generating spurious text, perhaps worse than ASCII translations.
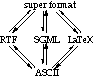
In a way ASCII acted as a common format and made the job of translating somewhat simpler (if less effective). An alternative is to look for a super-format which incorporates all the features of all the representations. Each format can then be translated to and from the super-format without loss of information.
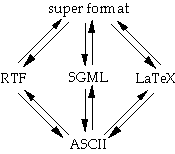
Figure 7 A common format?
Finding such a format is no mean task and experience shows that 'union' approaches to features, in any area of computing, lead to arcane notations, but, for the sake of argument, let's assume that we have such a format. It could work quite well for a central repository - each person could lodge their text there without any fear of losses when they next required it. However, if the same text is repeatedly accessed and updated by different people it will go through a series of translations. For example:
RTF -> super-format -> SGML -> super-format -> RTF
The first version in the super-format would retain all the presentation information of the RTF, but when this is translated into SGML, that information is lost, and will remain lost when the SGML is translated back into the super-format. So, the final result of this process is very much like that for simple translations - the intersection rather than the union of features.
The super-format approach does have some advantages, however. For any format one need only define a translator back and forth between this common format. In contrast, in order to translate to and fro between each of n formats we would need n(n-1) individual translators! Also, with a common format, there is less chance of losing information due to different assumptions made by the translators.
If a document is being sent repeatedly between two authors they may use their own means to reduce the cost of constant reformatting. Each author may keep a copy of the document in their own format; when an updated version arrives, they will edit their copy to incorporate any changes. Of course, the new text will require formatting in each representation, but this is certainly better than reformatting the entire document after each change!
This process depends on the authors:
The first can be aided by using a file difference tool (Neuwirth, Candhok et al. 1992), and some word-processors have such features built in. The second depends on their accuracy, but may be aided by cut-paste facilities between the out-of-date copy and the updated document.
These two requirements put a considerable strain on the authors, and almost inevitably the copies of the documents will become out of sync with one another, necessitating periodic complete reformats (but to whose copy!). However this approach does show most promise for minimising the work required for each change.
Happily techniques exist which make the partial automation of the above process possible. First of all let's clarify the requirements.
We keep a copy of the document in each format and these should all represent the 'same' document. By this we mean that the information that they could hold in common is the same. At very least, when rendered into ASCII all the documents should be identical. This first requirement can be formalised as an invariant which must always hold between the copies of the document.
When any copy of the document (say the RTF version) is updated by an operation 'o' we require equivalent updates on the other documents (os and ot) which maintain the invariant (see figure 8).
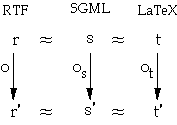
Figure 8 Parallel translations
This is a similar problem to maintaining the relationship between the internal state of an interactive system and its display (Harrison and Dix 1990; Dix 1991). When this process was studied some years ago, it was recognised that one of the crucial issues was the relationship between locations in each. This was formalised in the notion of dynamic pointers, which are both an analysis and implementation technique for maintaining the relationship between locations in different objects when they are updated. More recently it was realised that dynamic pointers had applications to various other aspects of cooperative work (Abowd and Dix 1992; Dix 1995).
This paper is aimed at describing the context and issues surrounding this problem and a formal account of the way dynamic pointers can solve this problem is found elsewhere (Dix 1995). In a nutshell, the process is as follows. A mapping is always maintained between equivalent locations in each copy of the document. When any copy is changed the region affected by the change is determined, either by the editor that performed the change or by use of a 'diff' tool tailored to the particular file format. The equivalent part of each other copy is then identified using the mapping between locations. All parts outside these regions are unchanged. The portion that changed is then translated into each of the other formats (using dedicated translators, ASCII, or some other common format) and this translated portion is 'glued' into place. The translators are required to give the relationship between locations in the parts they have translated. This information can then be used to update the mapping between locations in the different documents.
The result of this process is that each participant will find their copy of the document unaltered except for the actual new text (with all the formatting intact on the old material). The new material will have been incorporated using some default translation and so may need some tidying up, but the work is limited to that.
This paper shows how it is possible to automate the parallel development of a document in different formats. This can be combined with work on merging updates (Dix and Miles 1992; Munson and Dewan 1994) to give a robust platform for working at different locations and on different software and hardware platforms.
G. D. Abowd and A. J. Dix (1992). Giving undo attention. Interacting with Computers, 4(3) pp. 317-342.
A. J. Dix (1991). Formal Methods for Interactive Systems. Academic Press.
A. J. Dix (1995a). Dynamic pointers and threads.
Collaborative Computing, 1(3): pp. 191Å216.
A. J. Dix (1995b). Moving between contexts. Design, Specification and Verification of Interactive Systems '95, Eds. P. Palanque and R. Bastide. Toulouse, France, Springer Wien. pp. 149-173.
A. J. Dix and V. C. Miles (1992). Version control for asynchronous group work. YCS 181, Department of Computer Science, University of York, (Poster presentation HCI'92: People and Computers VII).
M. D. Harrison and A. J. Dix (1990). Modelling the relationship between state and display in interactive systems. In Visualisation in Human-Computer Interaction, Eds. P. Gornay and M. J. Tauber. Springer-Verlag. pp. 241-249.
J. Munson and P. Dewan (1994). A flexible object merging framework. Proceedings of CSCW'94, Eds. R. Furuta and C. Neuwirth. Chapel Hill, North Carolina, ACM Press. pp. 231-242.
C. M. Neuwirth, R. Candhok, D. S. Kaufer, J. Morris and D. Miller (1992). Flexible Diff-ing in a Collaborative Writing System. CSCW'92 - Proceedings of the Conference on Computer-Supported Cooperative Work, . ACM Press. pp. 147-154.
A. Schill (1995). Cooperative Office Systems. Prentice Hall.
M. Sharples, Ed. (1993). Computer Supported Collaborative Writing. Springer-Verlag.