Many sites now dynamically add content to a page as you scroll down; this includes both Facebook and Twitter feeds, which add content as you get near the bottom. In many ways this is a good thing, if users have to click to get to another page, they often never bother1. However there can be unfortunate side effects … sometimes making sites un-navigable on certain devices. There are particular problems on MacOS, due to the removal of scrollbar arrows, a usability disaster anyway, but confounded by feature interactions with other effects.
 A recent example was when I visited the SimoleonSense blog in order to find an article corresponding to an image about human sensory illusions. The image had been shared in Facebook, and I found, when I tried to search for it, also widely pinned in Pinterst, but the Facebook shares only linked back to the image url and Pinterst to the overall site (why some artists hate Pintrest). However, I wanted to find the actual post on the site that mentioned the image.
A recent example was when I visited the SimoleonSense blog in order to find an article corresponding to an image about human sensory illusions. The image had been shared in Facebook, and I found, when I tried to search for it, also widely pinned in Pinterst, but the Facebook shares only linked back to the image url and Pinterst to the overall site (why some artists hate Pintrest). However, I wanted to find the actual post on the site that mentioned the image.
Happily, the image url, http://www.simoleonsense.com/wp-content/uploads/2009/02/hacking-your-brain1.jpg, made it clear that it was a WordPress blog and the image had been uploaded in February 2009, so I edited the url to http://www.simoleonsense.com/2009/02/ and started to browse. The site is a basically a weekly digest and so the page returned was already long. I must have missed it on my first scan down, so I hit the bottom of the page, it dynamically added more content, and I continued to scroll. Before long the scrollbar handle looked very small, and the page very big and every time I tried to scroll up and down the page appeared to go crazy, randomly scrolling anywhere, but not where I wanted.
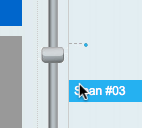 It took me a while to realise that the problem was that the scrollbar had been ‘enhanced’ by the website (using the WordPress infinite scroll plugin), which not only added infinite scrolling, but also ‘smart scrolling’, where a click on the scrollbar makes an animated jump to that location on the scrollbar. Now many early scrollbars worked in this way, and the ‘smart scroll’ options is inspired by the fact that Apple rediscovered this in iOS for touch screen interaction. The method gives rapid interaction, especially if the scrollbar is augmented by ‘tips’ on the scrollbar (see the jQuery smartscroll demo page).
It took me a while to realise that the problem was that the scrollbar had been ‘enhanced’ by the website (using the WordPress infinite scroll plugin), which not only added infinite scrolling, but also ‘smart scrolling’, where a click on the scrollbar makes an animated jump to that location on the scrollbar. Now many early scrollbars worked in this way, and the ‘smart scroll’ options is inspired by the fact that Apple rediscovered this in iOS for touch screen interaction. The method gives rapid interaction, especially if the scrollbar is augmented by ‘tips’ on the scrollbar (see the jQuery smartscroll demo page).
Unfortunately, this is different from the Mac normal behaviour when you click above or below the handle on a scrollbar, which effectively does screen up/down. So, I was trying to navigate up/down the web page a screen at a time to find the relevant post, and not caring where I clicked above the scroll handle, hence the apparently random movements.
This was compounded by two things. The first is a slight bug in the scrolling extension which means that sometimes it doesn’t notice your mouse release and starts scrolling the page as you move your mouse around. This is a bug I’ve seen in scrolling systems for many years, not taking into account all the combinations of mouse down/up, enter/leave region etc., and is present even in Google maps.
The second compounding factor is that since MacOS got rid of the scrollbar arrows (why? Why? WHY?!!), this is now the only way to reliably do small up/down movements if you don’t have a scroll wheel mouse or similar.
Now, in fact, my Air has a trackpad and I think Apple assumes you will use this for scrolling, but I have single-finger ‘Tap to click’ turned off to prevent accidental selections, and (I assume due to a persistent bug) this turns off the two finger scrolling gesture as well (even though it is shown as on in the preferences), so no scrolling from the touchpad.
Since near the beginning of my career I have been fascinated by these fine design decisions and have written previously about scrollbars, buttons, etc. They are often overlooked as they form part of the backdrop to more significant applications and information. However, the very fact that they are the persistent backdrop of interaction makes their fluid usability crucial, like the many mundane services, buses, rubbish collection, etc., that make cities work, but are often unseen and unnoticed until they fail.
Also note that this failure was not due to any single feature or bug, but the way these work together what the telephony industry originally named ‘feature interaction‘, but common across all technological systems There is no easy fix, apart from (i) thinking of all possible scenarios (reach for your formal methods in HCI!) and (ii) testing across different devices. And certainly (Apple please listen!) if it ain’t broke, don’t fix it.
Happily, I did manage to find the post in the end (I forget how, maybe random clicking) and it is “5 Ways To Hack Your Brain“. The individual post page has no dynamic additions, so is only two screens big on my display (phew), but still scrolled all over the place as I tried to select the page title to paste above!
- To my mind, early web guidance, was always wrong about this as it usually suggested making pages fit a screen to improve download speed, whereas my feeling, when using a slow connection, was it was usually better to wait a little longer for one big screen (you were going to have to wait anyway!) and then be able to scroll up and down quickly.[back]